








在互联网和W3C极大发展的今天,B/S(浏览器/服务器)模式已经成为了人们接触互联网最直接简单的方式。 而随着Node.js、React、Vue.js等等开源框架的发展,现在我能能通过浏览器前端做到更多事情。
而得益于标记语言(HTML,XML等)和解释型语言(JavaScript,Python等)的性质, 我们看到前端页面的内容基本都是这些语言通过浏览器解释渲染后形成的效果。 也就是说,你想在浏览器里看到前端页面,那么你的浏览器必需接收到这个页面的源码。 换言之,你得到了页面的源码,你就得到了这个页面上的一切内容。爬虫正是通过爬取网站前端源码来实现对页面进行分析的工具。
一、浏览网页时浏览器和服务器究竟在做着什么交易?
我们知道,浏览器是负责解释渲染的,那么他必须先拿到前端的源码才能开始它的工作。 所以,当我们访问一个网址的时候(这时候还会发生一些其他交易,与爬虫无关留作以后开坑), 服务器会将对应的前端页面直接(单纯的HTML页面)或经过编译(例如php后端)的源码文档发送到你的浏览器。 当你的浏览器拿到这些源码的时候,他就会着手将这些渲染成好看的前端页面。
所以,既然我们想分析一个网站的内容,那何不擒贼先擒王,直接将源码抢过来分析不就成了么,这也正式爬虫的目的。
二、啥?Requests是啥?
既然知道了爬虫存在的意义,那么我们先来了解一下如何用Python写出一个小爬虫。 在Python中,内置的urllib库给我们提供了很多访问网站的方法,比如urllib.urlopen()等。
但是,这个库并不好用,甚至还有些麻烦,一些高级的功能也无法实现。 那这个时候,就要请出我们今天的主角登场:requests库。它不仅优化了原有urllib的方法, 还添加了很多更加实用的方法。有了它,我们就能更加快乐地爬取网站了。
首先,让我们安装它。老办法,当然是要用pip工具。
pip install requests然后?还有然后么?用就行了。
三、一个极尽简单的小爬虫
# coding:utf-8
import requests # 导入requests包
response = requests.get(https://app.utopiaxc.com) # 构建一个简单的请求,这里是我的另一个网站
print(response.text) # 将获取的网站源码打印出来这是一个极度简单的小爬虫。我们可以看到,其实他的核心只有由一给函数构成,即
response = requests.get(https://app.utopiaxc.com)这句话实际上是requests利用了get方法从我的服务器请求了这个页面,然后利用print()将其打印出来。 我们可以看到,下面的运行结果中和之前我们在浏览器中查看的源代码一摸一样。
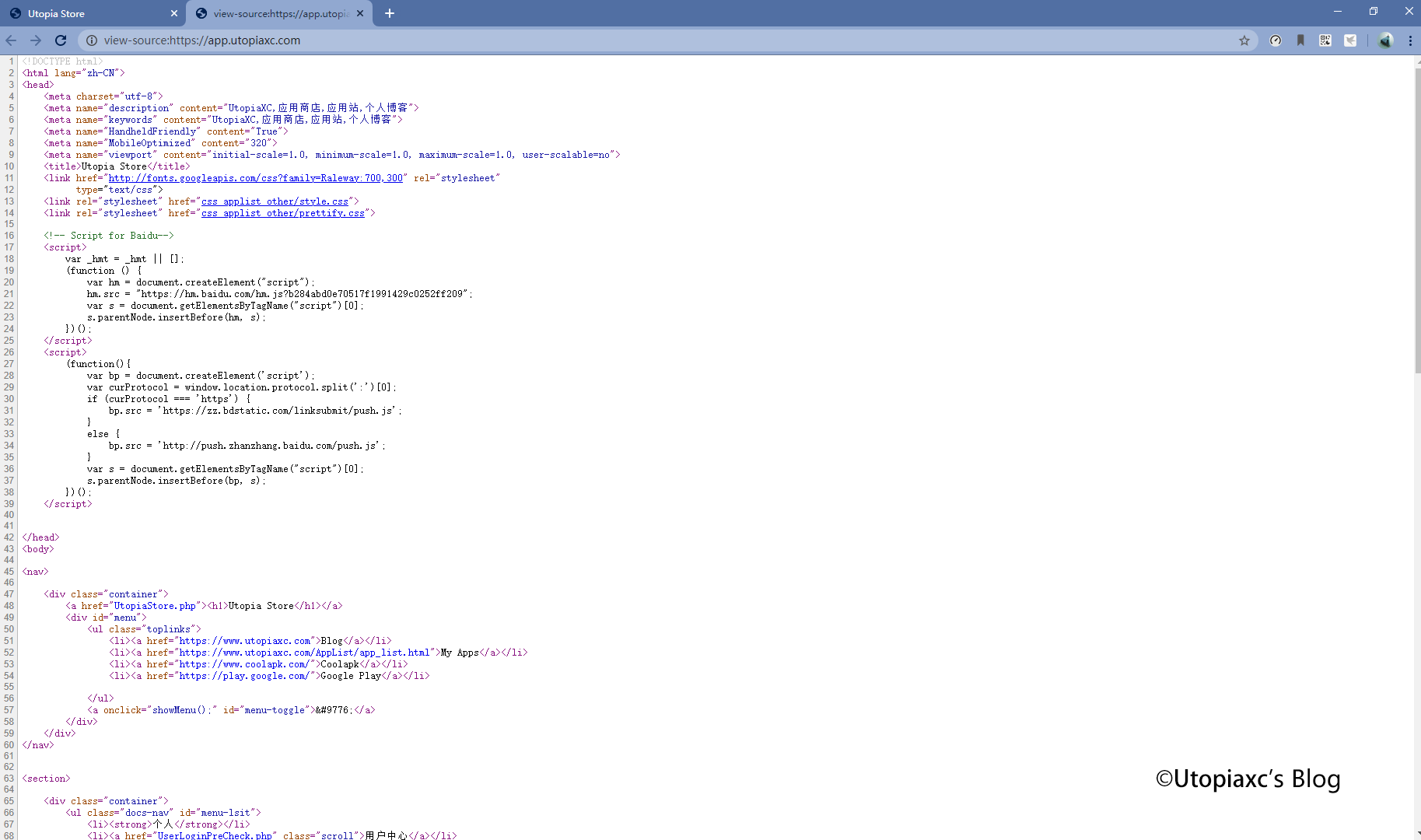
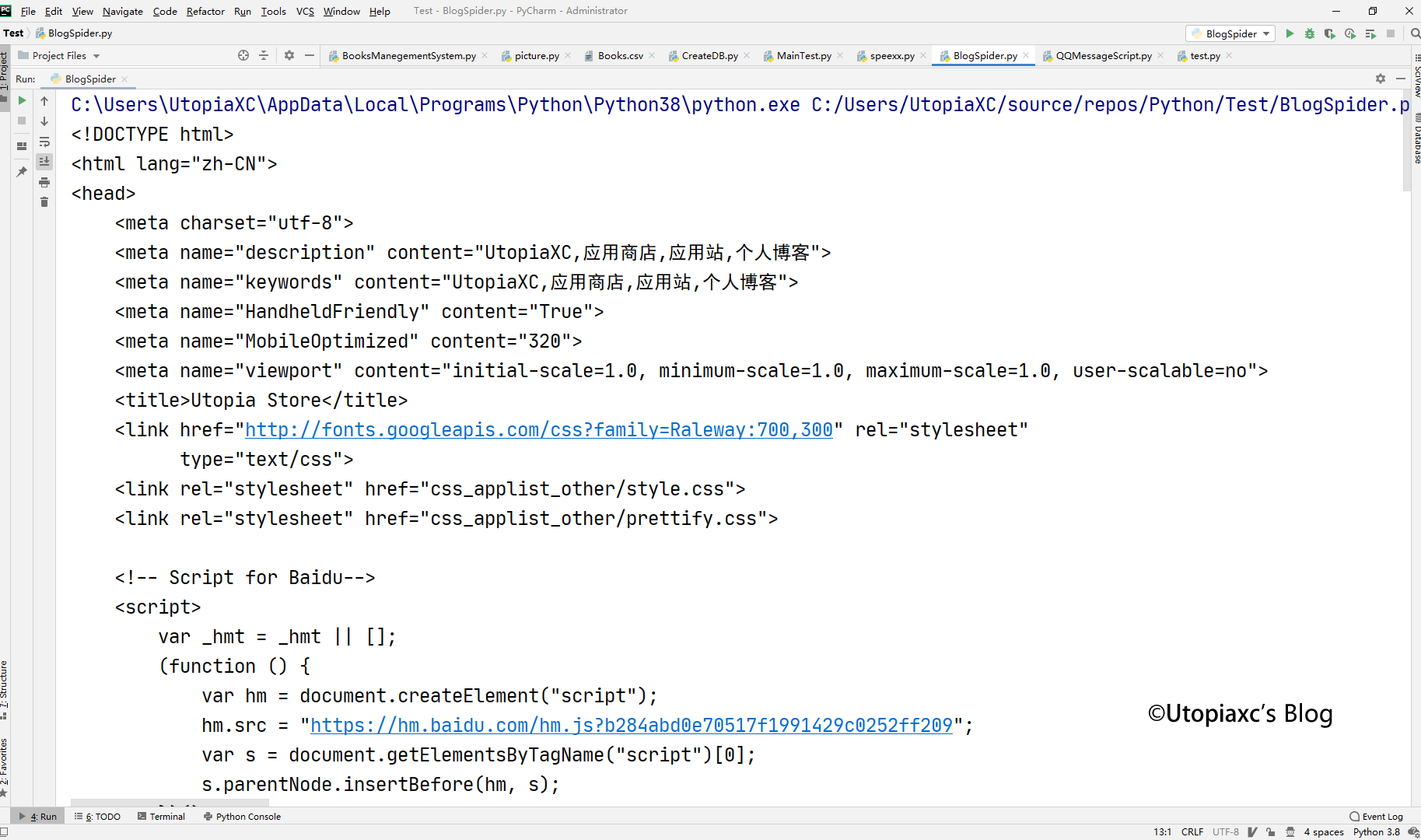
四、请求不到?那就高级一点
当然,出于某些目的,比如反爬虫,又或者是限制浏览器等,这么简单的爬虫并不能足以让我们访问一切网站。 那么,我们此时就要稍微拿出一点诚意,假装让浏览器感觉我们是浏览器用户,混入敌军之中。
在我们访问网站的时候,我们的浏览器会发送一个header,这个header中包含了很多信息,比如用户代理 (UserAgent)、比如地址(Host),比如语言(Accept-Language)等等。 而这其中的UserAgent便是识别浏览器型号的关键,因此,我们只需要提交一个假的UserAgent便可以蒙混过关。 至于怎么伪装,大家可以用我下面代码中给出的UserAgent(Chrome),也可以利用F12查看自己浏览器的UserAgent。
# coding:utf-8
import requests # 导入requests包
# 请求头字典,一般只需要UserAgent,具体情况具体分析
headers = {
'UserAgent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.122 Safari/537.36'
}
# 构建一个拥有UserAgent的请求,这里是我的另一个网站
response = requests.get(https://app.utopiaxc.com, headers=headers)
print(response.text) # 将获取的网站源码打印出来五、GET? POST?
大家可以看到,我刚才使用的均是get方法,那么get方法到底是什么呢? 而post方法又是什么呢?
我们不进行过多深究,可以简单地理解为,get方法就是向服务器请求获取一个页面, 这个页面的全部地址和表单信息都包含在url链接里面。比如“https://app.utopiaxc.com/AppDetails.php?aid=1000000010”。 这个链接中问后面就是表单信息,这个表单key为aid,value为1000000010。
而post也是一种请求页面的方法,而这种方法更加保守安全,他不会将表单信息体现在url中, 而且表单的内容可以更加丰富,比如一个视频。
那么什么是表单呢?表单就是用户自行提供的数据和信息。比如你在浏览器输入框中输入的密码, 比如在搜索框中输入的关键字,上传的文件等等,用户在浏览器上和服务器间的信息沟通基本都是通过表单进行的。
当然,这仅仅是形象地介绍了一下他们的区别,然而事实上,他们都是按照TCP标准进行请求的, 甚至,你照样可以在POST表单中添加GET表单,这都是可行的。然而,这就涉及到了另外一个知识, HTTP协议,我们这里不过多介绍,有兴趣的可以自己查找资料。
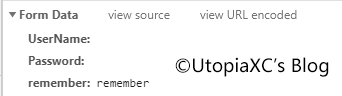
六、构造一个post请求来登录你的用户
我们刚才提到过,你和服务器间的通讯均是透过表单来完成的,那么, 我们一样也可以通过构造假表单来等我我们的账户。 依旧用我的应用站举例,可以看到,当你点击登录的时候,会将你输入的信息以表单的形式提交到服务器, 服务器后端接收信息并返回结果。
我们可以看到,这个表单由三个参数构成,即用户名密码和是否记住账户。 那么,我们只要模仿这个形式构造一个虚假的表单,就可以模拟登录这个操作。
# coding:utf-8
import requests # 导入requests包
# 请求头字典,一般只需要UserAgent,具体情况具体分析
headers = {
'UserAgent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.122 Safari/537.36',
}
# 构造一个表单字典
form = {
'UserName': 'USERNAME', # 设置用户名
'Password': 'PASSWORD', # 设置密码
'remember': 'remember' # 设置是否记住
}
# 构建一个具有UserAgent和表单请求,这里是我的另一个网站的个人中心
response = requests.post(https://app.utopiaxc.com/UserCenter.php,
headers=headers,# 设置headers
data=form)# 设置表单
print(response.text) # 将获取的网站源码打印出来七、cookies?饼干?
我们在网上冲浪的时候,经常有一些良心网站会提醒我们,该网站使用了cookie来保存用户信息。 那么,cookie到底是什么呢?难道网站在用饼干来保存我们的用户信息?
cookie,又称作甜饼,是一种小型的文本文件。他到底有什么用呢?举一个例子,我们经常在往上冲浪, 登录了一个网站之后,可能接下来一段时间都不需要重复登陆,又或者在不关闭浏览器之前你一直处于登录状态, 那这到底是什么做到的呢?难道我们的浏览器背着你保存了你的密码在你请求的时候自动登陆了么?
事实上,这个说法既正确又错误,浏览器的确记住了你的登录信息,但是不是保存了你的密码,而是cookie。 在你成功登录了或打开了一个网站的时候,网站的服务器会给你返回一长串字符串,这一串字符通常不明所以, 因为他们基本都被不可逆加密过,他们存在的意义是告诉浏览器和服务器拥有这个字符串的人已经打开或登陆过这个网站了。
通常,在服务器上会保存两套你的账户和密码,一套是你正常的账户名和密码,当然这个密码在服务器也是至少要进行MD5加密后才会进行保存的。 另一套就是cookie的Token。这个Token通常是随时间变化或浏览器UA或登录ip信息随机加密生成的。 这就是我们经常能在cookie中见到的用来保存登录状态的信息。一般,cookie都会设置失效时间, 比如,你在登录的时候并没有选择记住密码,那这个cookie的会在你关闭浏览器的时候从浏览器删除,同时, 在服务器端也不会再记录本次登录cookie。而如果你选择了记住,那么接下来一段时间内当你访问的时候, 浏览器会自动发送cookie,服务器经过比对,只要还没有超过有效期,就会判定为登陆成功。 但是通常,cookie生效期间你使用了没有保存该cookie的设备或应用登录,服务器就会产生一个全新的cookie,你原有的cookie信息就彻底失效了。
八、搞事!获取cookie并通过cookie登录!
既然提供了上述的cookie机制,那我们的爬虫想要在不同时间内爬取, 或者一次性爬取多个页面可就容易的多了。
我们依旧使用我的网站进行演示,这里我使用了一种很蠢但是很直观的方式来展现到底什么是cookie登录, 即先用密码登录,获取到cookie,然后携带cookie去访问相应页面。
# coding:utf-8
import requests # 导入requests包
# 请求头字典,一般只需要UserAgent,具体情况具体分析
headers = {
'UserAgent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.122 Safari/537.36',
}
# 构造一个表单字典
form = {
'UserName': 'USERNAME', # 设置用户名
'Password': 'PASSWORD', # 设置密码
'remember': 'remember' # 设置是否记住
}
# 构建一个具有UserAgent和表单请求,这里是我的另一个网站的个人中心
response = requests.post(https://app.utopiaxc.com/UserCenter.php,
headers=headers,
data=form)
print(response.text) # 将获取的网站源码打印出来
print(response.cookies) # 将cookie信息打印出来
cookies=response.cookies
# 虽然这里是使用cookie登录,但是我的网站依旧设置了一个表单检查
# 不过这个表单内不需要含有用户名和密码
form = {
'isCookie': '是'
}
# 访问第二个需要登录的页面
response = requests.post(https://app.utopiaxc.com/BackControl.php,
cookies=cookies, # 设置cookie
headers=headers, # 设置headers
data=form) # 设置表单
print(response.text) # 将获取的网站源码打印出来九、哈?麻烦死了?没有简单点的办法么?有!会话!
虽然,我们手动的来写cookie进行登录能让我们更直观的看到cookie,也可以让我们有更大的发挥空间, 比如我们不登陆,去浏览器上获取cookie,然后用浏览器的cookie复制粘贴下来不就行了嘛! 但是,对于我们上面的情景,就十分麻烦了,因为我们要一个进行读取cookie的过程。这个时候, 就该引入我们的会话机制了。
那么,到底什么是会话呢,当我们打开浏览器,打开了一个网站,那么我们就开始了一次会话。 这个会话其实是基于cookie的,所以在一次会话内我们才能不断地访问需要输入密码的页面。 但是会话又让我们不用自行的去输入cookie,只需要开启一次会话,那么cookie都会保存在这次会话之中不需要单独提取。
# coding:utf-8
import requests # 导入requests包
# 请求头字典,一般只需要UserAgent,具体情况具体分析
headers = {
'UserAgent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.122 Safari/537.36',
}
# 构造一个表单字典
form = {
'UserName': 'USERNAME', # 设置用户名
'Password': 'PASSWORD', # 设置密码
'remember': 'remember' # 设置是否记住
}
session = requests.Session() # 开启一次会话
# 构建一个具有UserAgent和表单请求,这里是我的另一个网站的个人中心
# 利用会话来post请求,会话会自动保存cookie
session.post(https://app.utopiaxc.com/UserCenter.php,
headers=headers,
data=form)
# 虽然这里是使用cookie登录,但是我的网站依旧设置了一个表单检查
# 不过这个表单内不需要含有用户名和密码
form = {
'isCookie': '是'
}
# 访问第二个需要登录的页面
# 利用会话来post请求,会话会提交cookie
response = session.post(https://app.utopiaxc.com/BackControl.php,
headers=headers, # 设置headers
data=form) # 设置表单
print(response.text) # 将获取的网站源码打印出来十、什么?!网站竟敢封我IP?代理吧,少年。
注意:违法是不行的!大规模恶意使用IP代理导致经济损失的会被判处毁坏计算机系统罪哦
一般来说,网站服务器的网络和CPU资源开销是很大的, 而能承受大规模并发的带宽和处理器又十分昂贵,因此大部分网站是不希望被用户频繁爬取的。 比如我的网站,为了防止CC(可以理解为页面版的DDoS)攻击,每分钟请求次数过的IP将会遭到一定时间的封禁, 因此会影响很多爬虫的性能。(当然影响不到爬取我的网站,毕竟一共没有几个页面)
那么,解决这个问题的最简单的办法是,代理。利用IP代理池来装做你的请求是从世界各地来的, 这样服务器就无法判断你是正常流量还是非法流量,因此更难进行封禁。(当然还是有一些办法的, 比如高防服务器,比如IP段封禁等等)
所以,想要一个大规模反复爬取一个网站你就需要一个IP池,这个IP池你可以通过自己购买或租赁具有公网IP的服务器 (成本爆炸),可以去运营商申请专线网络和公网IP(成本核爆),也可以使用一些公用的黑池子, 当然黑池子一般都是肉鸡,很不安全,而且容易被封。
当然,除了防止IP封禁,代理还可以用来爬取一些国内无法直接访问的网站,比如404小网站Google等。
# coding:utf-8
import requests
# 设置HTTP/HTTPS代理
proxies = {
http: http://xxx.xxx.xxx.xxx:xxxx,
https: http://xxx.xxx.xxx.xxx:xxxx
# 如果代理需要进行登录,则写法为:http:http://user:passwd@xxx.xxx.xxx.xxx:xxxx
# 代理地址为域名或ip加端口号
# 如果想使用socks代理需要安装其他依赖库,请自行搜索
}
response = requests.get(https://app.utopiaxc.com, proxies=proxies)
print(response.text)
本篇内容为原创内容,采用CC BY-NC-SA 4.0协议许可
2020-4-26 18:25
UtopiaXC
于大连
Comments | NOTHING